发布日期:2026/3/31 12:51:19 访问次数:114
今日金价,一克 1000.06 元;
95 号汽油,每升 8 块 5 毛 7;
电费是阶梯计价,家庭用电最多每千瓦时 8 毛 9;
……
克、升、千瓦时——单位一旦确定,便可以被标注价格,而价格决定了消费,也潜移默化地塑造着每个人的生活。大多数时候,我们并不关心这些单位本身,只要它们足够稳定,稳定到可以比较、可以结算,它们就会默默隐藏自己,退回到缴费单和购物小票背后。
但现在,一种全新的、陌生的计量单位,正浮出水面,走入更多人的生活。
它叫 Token。
如果你最近玩过、听说过,甚至自己试着调用过各种 AI 助手或“智能体”(比如近期流行起来的 Openclaw “小龙虾”),那么你应该已经和它打过照面了。你与 AI 的每一次对话,无论是让它回答一个问题、写一封邮件,还是总结一篇论文,后台那个默默跳动的计价数字,单位就是 Token。
Token,就是 AI 世界的“克”“升”和“千瓦时”。

Token 到底在计量什么?
在 OpenAI 的官方页面上,用一句话简单地概括了 Token:Token 是自然语言的数学表示。
在中文里,Token 常被翻译为“词元”,你可以将它理解成为大模型用来处理自然语言的基本单位,或大模型处理信息的最小信息单元。一段话、一个问题在进入 AI 模型被计算机处理前,首先要被“分词器(Tokenizer)”拆分成一个个 Token。
一个 Token 可能是一个标点、一个汉字、一个英文单词,或者一个常见的词组——这取决于不同 AI 模型分词器的设计。比如“朋友买了西瓜手机!”可能被拆为“朋友”“买”“了”“西瓜”“手机”“!”,“Transformer”可能被拆成“Trans”“former”。
这些被拆分好的 Token,对于你我来说是有意义的文字,但对于大模型而言,它并不认识,更不理解。为了让 AI “理解”,大模型会先给每个 Token 分配一个数字编号,然后将这个编号转化为一组数字坐标(向量)。这个坐标决定了 AI 如何“理解”这个词。
更重要的是,AI 理解任何一个词,都要看它和其他词的关系。比如“西瓜”这个词,AI 在训练中既见过它和“手机”“汽车”“公司”“发布会”一起出现,也见过它和“吃”“食物”“好吃”一起出现。当 AI 看到“西瓜手机”这个组合时,它会通过“汽车”这个词的坐标,来调整“西瓜”在当前这句话里的含义——让它的坐标更接近“品牌”,远离“食物”。
AI 的整个“思考”过程,就是计算一整句话里所有 Token 坐标之间的复杂关系。它不会死记硬背“西瓜=品牌”或“西瓜=食物”,而是根据上下文动态计算。

聊到这里,你还会以为,Token 的消耗就是你输入和输出的字数简单相加吗?接下来,我们通过一次普通对话,看看 Token 到底是如何被消耗掉的。
我们让 AI 写一封信给十年后的自己:

指令输入十几个字,AI 回复四五百字,看起来不过几百个Token,但事实上消耗的 Token 远不止屏幕上那几行字:
系统预设指令(System Prompt):在你开口之前,AI 已经被输入了一段看不见的指令,被用来规定和你聊天的 AI 的身份,语气,回复用词特征和安全边界。很多人会感觉不同公司的 AI 产品有不同的性格特征,秘密就在这里。这段指令不会显示在对话中,但是也参与了模型的计算,会消耗掉一部分 Token。
对话的历史上下文(Context):如果你不是次提问,模型通常就需要考虑之前的上下文信息,才能知道整个对话在聊什么,保证对话的连续性。所以之前的提问与它之前的回答,都会进入最新这轮对话的计算。也就是说,对话越长,对话的轮次越多,最新的单轮请求消耗的 Token 也就越多。
思考过程(Reasoning):这是更隐蔽的消耗,很多具备深度推理模式的模型,在回答之前,它会进行一轮内部计算去比较推演不同的回答,最终将它认为最优的回答呈现出来。这些不展示出来的“思考步骤”,同样消耗资源。
总之,Token 计量的,并不只是你看到 AI 模型给出的答案,而是生成这个答案所需的全部计算资源。而进入以 Openclaw 为代表的 agent 场景,这种 Token 的消耗会被指数级扩大。
比如让一只小龙虾替你干活,把“帮我整理一下文件夹”这句话甩给它之后,它可能需要先读懂这个要求,然后拆解成十几个子任务,每个子任务分别调用一次 AI,每次调用都带着完整的系统指令和上下文,必要的时候还要反复检查有没有做对,是否需要修正。
这背后可能是几十轮对话、几万个 Token 的连锁消耗,这也是它看起来只干了点普通的活,但却格外消耗 Token 的原因。
为什么“输出 Token”比“输入 Token”贵 6 倍?
关于 Token 的价格,很多人可能没什么感知,毕竟无论和哪个 AI 聊天,对话 Token 的消耗都打包在了免费额度或者订阅制里,很难直接感受到。
我们以 OpenAI 为例,来研究一下它的价格表:
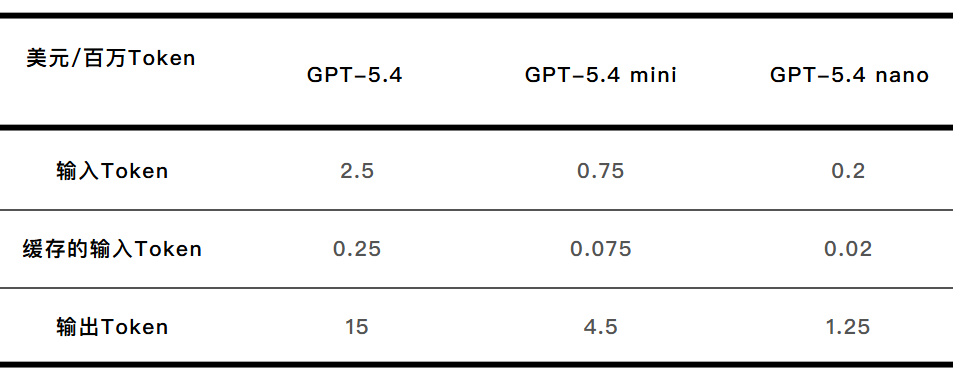
可以看出,模型越强大,Token 越贵,从 Nano 到标准版,每百万 Token 价格差距高达十倍。这很容易理解:参数规模越大、模型能力越强,越能解决越复杂问题的模型,Token 的价格当然越贵。
而对比起不同公司,同为目前的 AI 模型,每百万 TokenGPT-5.4 的报价是 15 美元,Claude Opus 4.6 是 25 美元,Gemini 3.1 Pro 的报价则根据 prompt 长度不同列出了 12 美元和 18 美元两个价格。差距依然存在,这里的定价策略就比较复杂了,公司的定位与商业模式,模型的成本、受众、能力都会有所影响。
这些道理都很容易理解,但真正的谜题还不是这个。仔细看看,同一个模型的“输入 Token”和“输出 Token”竟然也存在 6 倍的定价差距,这是怎么回事?
输入(prefill)的时候,AI 要理解你的全部问题,每个词都要和其他所有词做关联计算(即“自注意力机制”,计算量会随着文本长度的增加急剧增长);而输出(decode)时,模型已经将输入的内容分析计算完毕,只需要把结果一个字一个字“吐”出来即可,似乎应该更轻松才对。
其实,答案并不在计算量,而在计算效率上。
处理输入时,所有的 Token 都是同时送入处理器的,成千上万个计算核心并行运行,这是大规模的矩阵乘矩阵运算,GPU 本来就是为了这种大规模并行计算而设计的。所以在应对这类任务时,计算效率极高,甚至可以说在允许范围内,Token 输入越长,越容易让 GPU 的计算核心接近满载工作状态。
但输出的时候,情况截然相反了。模型必须一个 Token 一个 Token 生成回答,每一个都需要依赖上一个生成的结果,无法并行展开。每次生成,模型都需要从显存中读取一次参数,同时结合已经生成的上下文进行计算,整体更接近矩阵乘向量的运算。
这个过程的瓶颈取决于内存带宽,也就是说,GPU 绝大多数时间没有在计算,而是在等待数据从显存被传过来,真正做计算的时间占比仅有 1%~5%,计算效率骤降。
用更准确的话说,处理输入是计算密集型(compute-intensive)工作,GPU 在做它最擅长的事,生成输出是内存带宽密集型(memory-bound)工作,GPU 的计算核心大部分时间在空转等数据。
所以,输出 Token 的高昂价格,本质上是在为一块每小时租金几美元的芯片,以不到百分之一的效率运转而被迫等待的时长付费。
这也就是为什么即使是同一种模型,输出 Token 的价格会比输入 Token 贵那么多,这是算力和内存带宽之间根深蒂固的不对称不匹配
有限公司")